고정 헤더 영역
상세 컨텐츠
본문
"모델은 열심히 만들었는데 서비스화 가능할까?"
모델을 만드는것과 서비스화 하는것은 다르기때문에 고민이 많아짐.
서비스 한다고 가정할때에 가장 걱정되는것은?
1. 데이터 드리프트
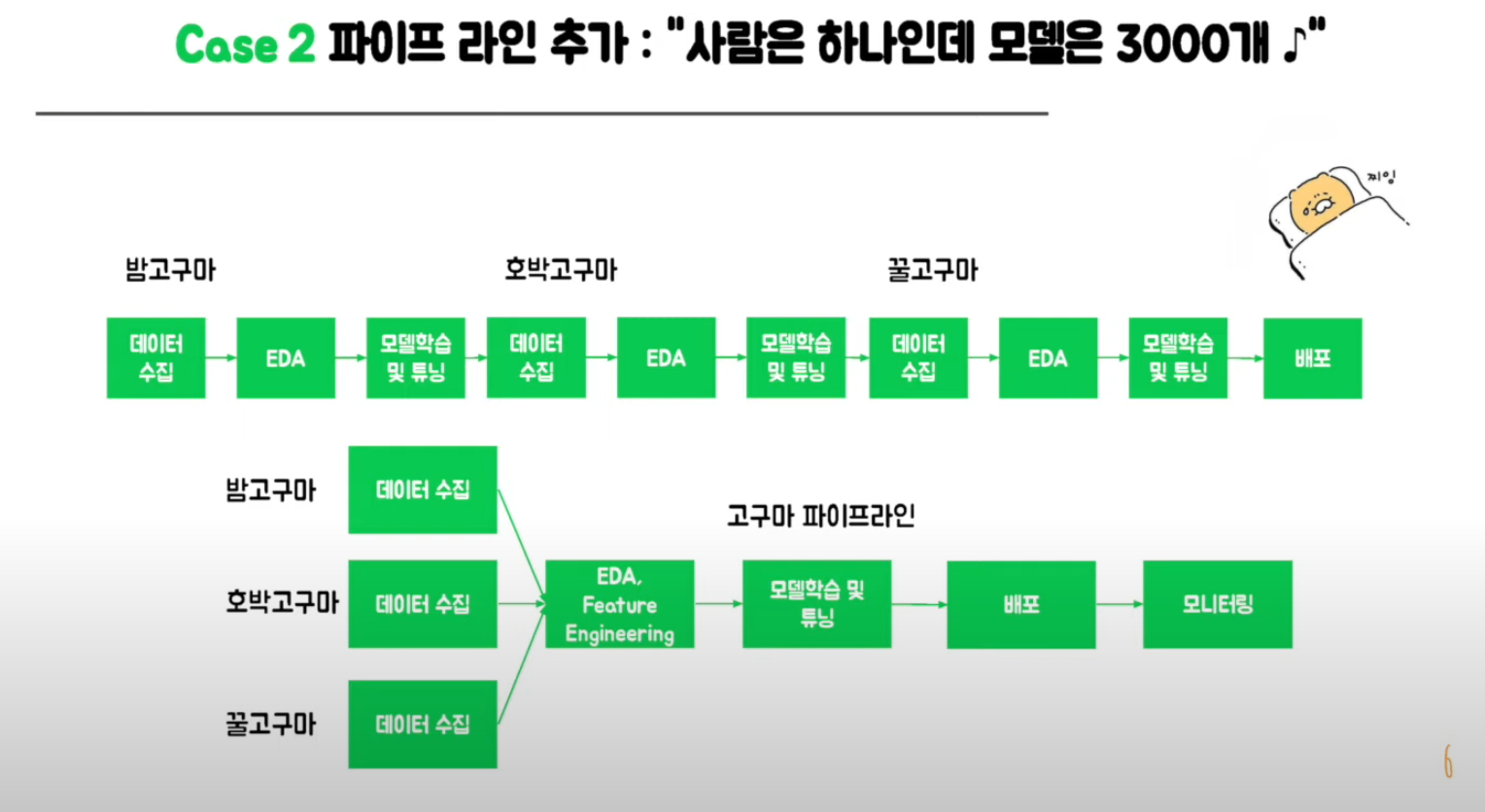
지속적인 재학습으로 파이프라인이 추가된다면?
공통된 부분 재학습이 효율적.
모델의 실질적인 서비스화 부분들에 대해 고민
2. 프로젝트 구조
PREFECT와 RAY를 통해 모델 학습
그것을 클라우드 스토리지와 DB에 저장
저장된 모델을 FAST API서버로 전달하여 천달
각각의 연결고리로 MLFLOW를 사용하였고
환경은 쿠버네티스로 관리

매번 하이퍼파라미터 튜닝 -> MNI와 RAY같은 라이브러리 도입하여 연구자가 조금 더 생산적인 업무에 집중할수있도록 처리
모델 관리 측면 - 모델이 잔뜩 쌓여감 - MLFlow통해 간편하게 관리

모델 로드 및 캐싱
모델 서빙까지 목표로 함
서비스 속도에 대한 고민도 함
클라우드 스토리지를 도입하여 로컬모델 불러오는 속도보다 느려짐
해결하기 위해 레디스 캐싱 이용함

레디스만으로도 응답속도를 많이 개선했지만 직렬화하고 다시 역직렬화하는 부분에서 지연됨.
불필요한 과정이라 생각하고 파이썬에 변수로 저장해두고 일정 시간이상 지나면 삭제해주는 변수 캐싱방법을 시도함
성능이 많이 개선됨

코드 퀄리티
지저분한 코드
프리 커밋을 도입하여 일정 퀄리티 이하의 코드는 업로드되지 않도록.
서버를 사용하다보면 서버 모니터링이 필요함
따라서 프로메테우스를 통해 서버 모니터링을 하면서 시각화까지 가능했음.
추후에는 슬랙 알림또한 추가할 예정
프로젝트를 만드는 과정에서 프리펙트, 패스트api, 포스트그레스, mlflow, 리액트, 그래파나 등 컨테이너를 많이 생성되기 때문에 쿠버네티스를 도입하여 별도의 도구 추가 없이 git action과 쿠버네티스 기능을 이용하여 지속적이고 중단 없는 배포가 가능했음
또한 쿠버네티스 컨ㅇ피그캡과 시크릿을 통해 보안에 민감한 데이터들을 안전하고 명시적으로 관리.
'MLOps' 카테고리의 다른 글
| [우아한테크세미나] MLOps를 활용한 AI 서비스 개발 스토리 (0) | 2024.04.08 |
|---|




